今天來看看 node shutdown 有哪些需要注意的事項吧 ~
https://kubernetes.io/docs/concepts/cluster-administration/node-shutdown/
node 可能會因為某些原因關機 (e.g. 跳電),而這又分成 graceful 和 non-graceful 的情況
當 node 關機時,kubelet 會嘗試讓 pods 走常規的 pod termination process 流程
在 node shutdown 期間,kubelet 並不會接受新的 pods (即使 pods 已經與 node 綁定)
在 k8s 1.21 之後,GracefulNodeShutdown 預設就是被打開的
而要啟用 graceful node shutdown,還需要設定 shutdownGracePeriod 與 shutdownGracePeriodCriticalPods ,這兩個值預設為 0,設定一個非 0 的數字即可啟用
在 node 關機期間,kubelet 會將 node 的狀態設定為 NotReady,且 reason 為 “node is shutting down”。kube-scheduler 看見此情況後,就不會把 pod 排過去 (其他第三方實作的 scheduler 也預期符合此邏輯)
shutdownGracePeriod:設定一個 delay 的時間,當 node 關機時寬限多久,此設定涵蓋 “regular pods” 與 “critical pods”
shutdownGracePeriodCriticalPods: 設定 critical pods terminate 的時間,此數值不能超過 shutdownGracePeriod
舉例來說,當shutdownGracePeriod=30s, shutdownGracePeriodCriticalPods=10s 的配置下,node 總共會有 30 秒的關機時間,前 20 (30-10) 秒會先處理 normal pods,後 10 秒會留給關閉 critical pods
筆者目前還不太確定特別分成 critical pods 會比較後面處理的原因 (推測是可以提供較長的服務?)
延伸閱讀:如何把 pods 指定為 critical pods :https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/#marking-pod-as-critical
主要是用於那些最重要會影響到叢集服務的 pods
除了上面把 pods 二分法以外,也可以透過設定 Priority 來指令 terminated 的時間
是設定在 kubelet 內,範例如下:
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 300
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60
Priority 越高代表越重要,也就預留最多時間
若是強制關機的情況,就不會觸發 kubelet 的 Node Shutdown Manager 機制,會導致:
可以透過打上 taint node.kubernetes.io/out-of-service 觸發,強制把 terminating 的 pods 重啟:
kubectl taint node k8s-master3 node.kubernetes.io/out-of-service:NoExecute
註:要確保 node 已經關機完畢,才可以打上此 taint (不要在 restarting 的過程中)
當 node 正常啟用後,也要手動把此 taint 移除,node 才會回歸正常狀態
給上此 taint 之後就會觸發:
當 pods 刪除卡住時,持續超過 6 分鐘後,k8s 會強制拔除所有的 volume (若有設定 “Non-graceful node shutdown”)
在 kube-controller-manager 內有個參數:disable-force-detach-on-timeout,設定過後就算超過 6 分鐘也不會把不健康的 node 上的 VolumeAttachment 刪掉
不會自動刪除,意即需要手動移除,可以參考上面打 taint 的方式,但要小心有可能會導致資料的損失。
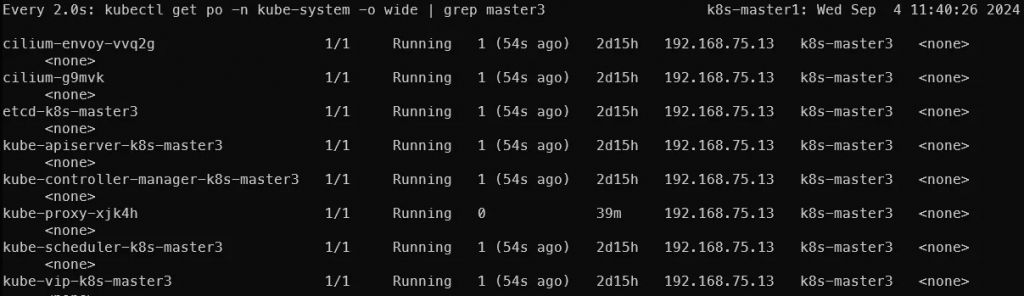
上圖是我將 master3 關機一段時間後再打開,可以發現 pods 都有重啟的情況
不過關機期間 pods 都是維持 running,這感覺不太合理,但也有看到討論說 daemonset 會 running 是正常的
此篇解釋了 kubelet 在針對 node 正常/非正常關機時的應對方式,也可以透過定義 priority 來決定哪些 pods 是相對較重要的。
另外 k8s node 在關機時有不少需要注意的,在 node 被標註為 Not Ready 後,其實會有不少奇怪的情況,例如 daemonsets, static pods 都還會是 running 的狀態
這個問題目前筆者還沒找到好的解釋…
打算明天來看看 pod 的 Lifecycle,或許可以找到解答
https://kubernetes.io/docs/concepts/cluster-administration/node-shutdown/
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination
https://kubernetes.io/blog/2023/08/16/kubernetes-1-28-non-graceful-node-shutdown-ga/

